
- All
- Apache Kafka
- Artificial Intelligence
- Bayesian Statistics
- Big Data
- Cassandra
- Computer Vision
- Data Engineering
- Data Science
- Database
- Deep Learning
- DevOps
- Django
- Docker
- ELK
- Feature Engineering
- Finance
- Keras
- Linear Algebra
- Linux
- Machine Learning
- Mathematics
- MLOps
- NLP
- Python
- PyTorch
- Recommendation Systems
- Reinforcement Learning
- Software Engineering
- Spark
- Statistics and Probability
- Tensorflow
- Time Series
- Uncategorized
2022-08-01
12 mins read Table of Contents: Introduction Are you looking for that instrumental version of your favorite song? Or are you a DJ […]
2022-08-01
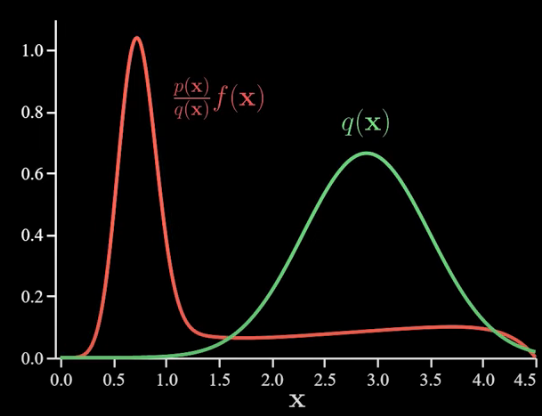
16 mins read Introduction In this post, I’m going to explain the importance sampling. Importance sampling is an approximation method instead of a […]
2022-04-08

4 mins read MinIO is a high-performance object storage solution with native support for Kubernetes deployments that provides an Amazon Web Services S3-compatible […]
2022-03-28
5 mins read Table of Contents: Introduction About bulkboto3 Getting Started Prerequisites Installation Usage Contributing Conclusion Introduction “How to transfer a bulk of […]
2021-12-26
{kind=link}
{kind=link}
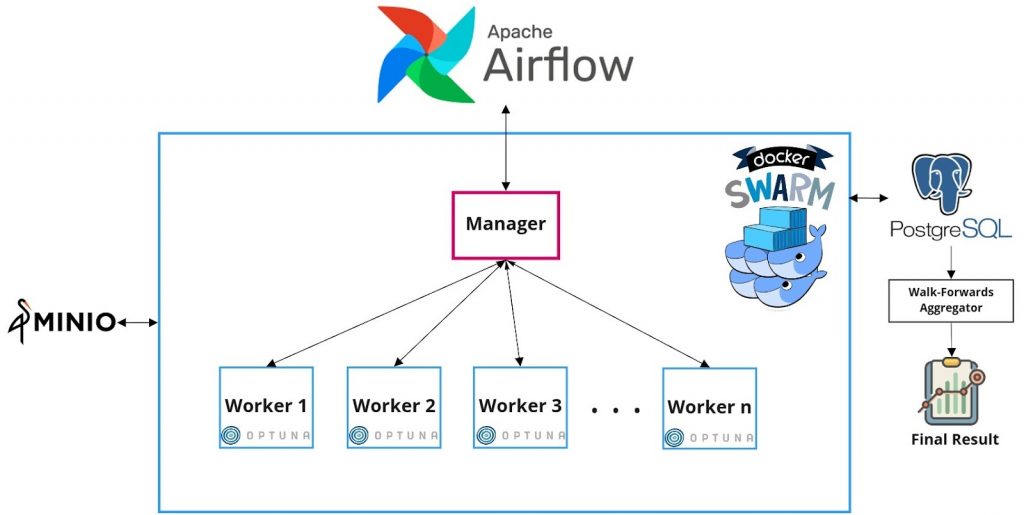{kind=link}
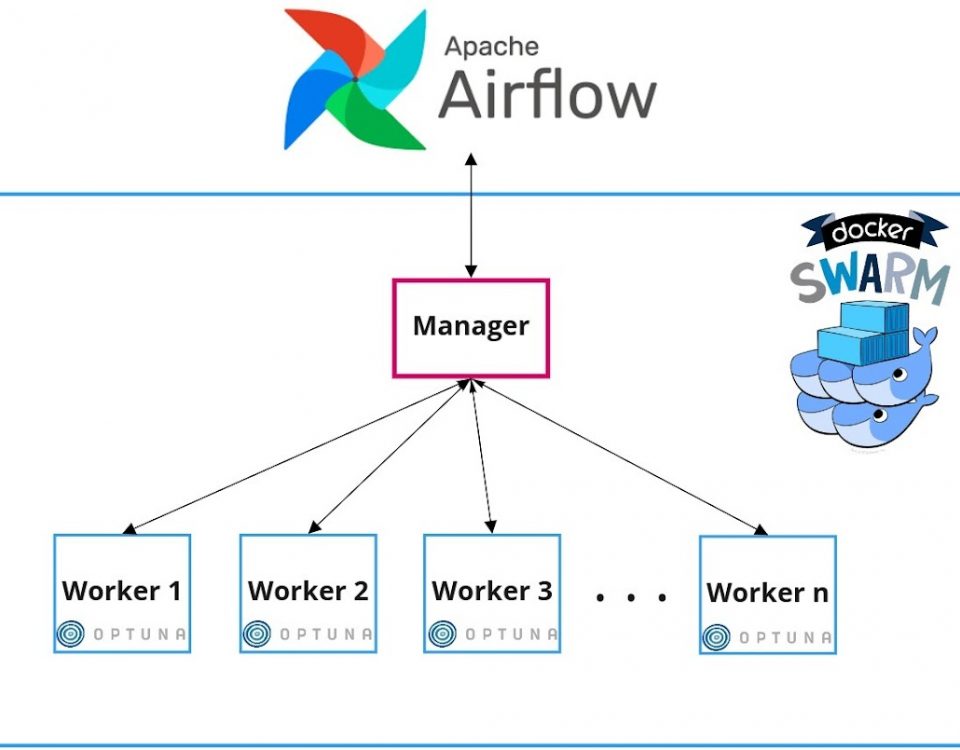
11 mins read Table of Contents: Introduction Terminology Walk-forward Optimization Design of walk-forwards The Architecture Configuring cloud machines using Ansible Docker Swarm Optimization […]