
A simple tutorial on Sampling Importance and Monte Carlo with Python codes
2022-08-01
A tutorial on Apache Cassandra data modeling – RowKeys, Columns, Keyspaces, Tables, and Keys
2022-08-11Table of Contents:
- Introduction
- Source Separation Problem
- Source Separation Use Cases
- Deep Model Architecture
- Architecture
- Training
- Output Signal Reconstruction
- Sample Results
- Other Features
- Conclusion
Introduction
Are you looking for that instrumental version of your favorite song? Or are you a DJ that needs instrumentals for your next DJ set? Are you looking for the instrumental stems of a famous song to create the next remix or mash-up as a producer? Or are you someone just like me who wished he could sing his favorite song in his own voice?
Generally, the question of “How to remove vocals from a song?” has been a question and a problem that many people asked for many years. I have had that question as well for several years. I tried and tested most of these vocal remover practices, but none of them were up to the quality standard that I wanted. Back then, to remove vocals from music, I either used Audacity’s Vocal Reduction and Isolation effect or an audio phasing cancellation technique. The result was often not that great because the vocal remover effects depended on frequencies and center-panned audio, to work (most tracks have the vocals mixed to its center).
So as an AI geek I decided to use Deep Learning and Python skills to develop my own AI-Based vocal remover system! While it may not be possible to completely remove vocals from songs due to elements such as frequency spectrum, stereo image separation, compression, and other issues, I achieved a stem separation at a never ‘heard’ before quality. Although the network is mainly trained on Pop English Songs, it can greatly generalize and separate vocals from songs in different languages, different genres, and even low-quality old ones.
I have implemented a web application including different dashboards to make the separation process easier for users (instead of running just a python script). Now, this product is used for commercial purposes and I’m afraid that I can’t share the codes or deep learning models. However, I will give an overview of architecture in this post.
Music always helped me to stay happy and motivated in my life. I have created this system for those willing to experience music not only by listening to it but also by playing or singing along to their favorite songs, just like me! I believe that music has the greatest healing power of all the things that humans ever invented. The more you are in it, the better it works!
Note: Originally, I developed the engine of this product in 2020 when there weren’t many applications for audio source separation. At the time that I decided to share this post (2022), you will certainly find more complex (and probably better quality) approaches.
Source Separation Problem
Source Separation is the process of isolating individual sounds in an auditory mixture of multiple sounds. We call each sound heard in a mixture a source. For example, we might want to isolate a singer from the background music to make a karaoke version of a song or isolate the bass guitar from the rest of the band so a musician can learn the part. Put another way, given a mixture of multiple sources, how can we recover only the source signals we’re interested in?
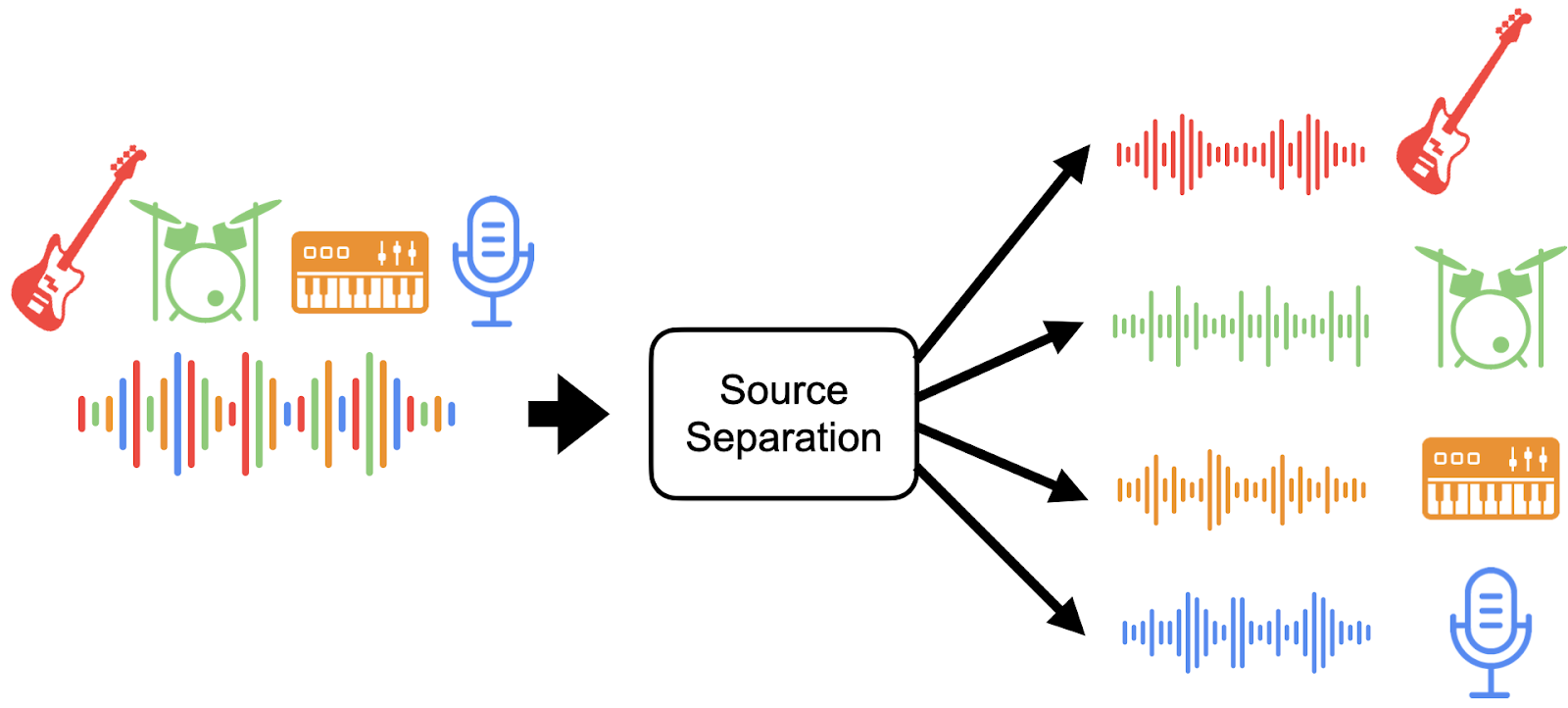
Source Separation Use Cases
One might be interested in using existing methods to enhance a downstream task, or one might be interested in source separation as a pursuit in itself. There are many demonstrated uses for music source separation within the field of Music Information Retrieval (MIR). In many scenarios, researchers have discovered that it is easier to process isolated sources than mixtures of those sources. For example, source separation has been used to enhance:
- Automatic Music Transcription
- Lyric and music alignment
- Musical instrument detection
- Lyric recognition
- Automatic singer identification
- Vocal activity detection
- Fundamental frequency estimation
- Understanding the predictions of black-box audio models
Additionally, source separation has long been seen as an inherently worthwhile endeavor on its own merits. As for commercial applications, it is evident that the karaoke industry, estimated to be worth billions of dollars globally, would directly benefit from such technology.
Deep Model Architecture
Without going too deep into the details of the utilized deep models, I will just provide an overview of the architecture in this section.
Architecture
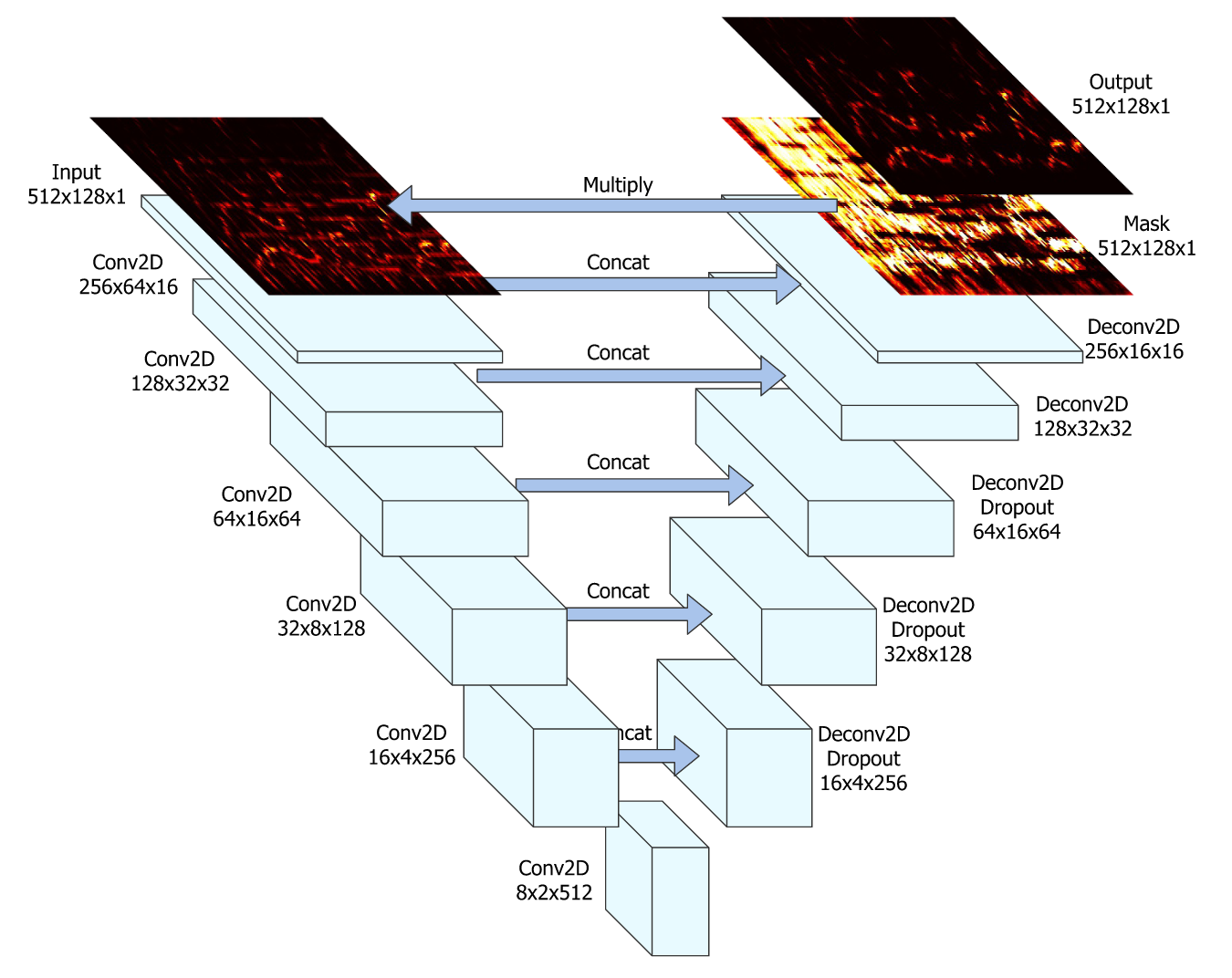
I used the U-Net architecture for the vocal separation engine. The architecture was introduced in biomedical imaging, to improve the precision and localization of microscopic images of neuronal structures. The architecture builds upon the fully convolutional network and is similar to the deconvolutional network. In a deconvolutional network, a stack of convolutional layers, where each layer halves the size of the image but doubles the number of channels, encodes the image into a small and deep representation. That encoding is then decoded to the original size of the image by a stack of upsampling layers [2].
U-Nets are a very popular architecture for music source separation systems. U-Nets input a spectrogram and perform a series of 2D convolutions, each of which produces an encoding of a smaller and smaller representation of the input. The small representation at the center is then scaled back up by decoding with the same number of 2D deconvolutional layers (sometimes called transpose convolution), each of which corresponds to the shape of one of the convolutional encoding layers.
In the reproduction of a natural image, displacements by just one pixel are usually not perceived as major distortions. In the frequency domain, however, even a minor linear shift in the spectrogram has disastrous effects on perception: this is particularly relevant in music signals, because of the logarithmic perception of frequency; moreover, a shift in the time dimension can become audible as jitter and other artifacts. Therefore, reproduction must preserve a high level of detail. The U-Net adds additional skip connections between layers at the same hierarchical level in the encoder and decoder. That is, each of the encoding layers is concatenated to the corresponding decoding layers. This allows low-level information to flow directly from the high-resolution input to the high-resolution output. Fig. 1 shows the network architecture.
The goal of the neural network architecture is to predict the vocal and instrumental components of its input. The output of the final decoder layer is a soft mask that is multiplied element-wise with the mixed spectrogram to obtain the final estimate.
Training
Let  denote the magnitude of the spectrogram of the original, mixed-signal, that is, of the audio containing both vocal and instrumental components. Let
denote the magnitude of the spectrogram of the original, mixed-signal, that is, of the audio containing both vocal and instrumental components. Let  denote the magnitude of the spectrograms of the target audio; either the vocal or the instrumental component of the input signal.
denote the magnitude of the spectrograms of the target audio; either the vocal or the instrumental component of the input signal.
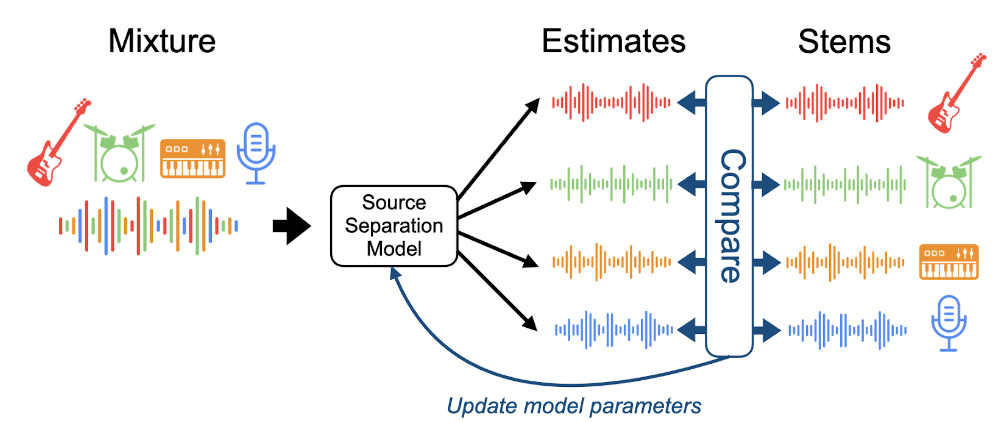
The loss function used to train the model is the L1 norm of the difference between the target spectrogram and the masked input spectrogram:

where  is the output of the network model applied to the input X with parameters
is the output of the network model applied to the input X with parameters  , that is the mask generated by the model.
, that is the mask generated by the model.  means element-wise or Hadamard product. The model was trained using the ADAM optimizer. Because the U-Net is convolutional, it must process a spectrogram that has a fixed shape. In other words, an audio signal must be broken up into spectrograms with the same number of time and frequency dimensions that the U-Net was trained with.
means element-wise or Hadamard product. The model was trained using the ADAM optimizer. Because the U-Net is convolutional, it must process a spectrogram that has a fixed shape. In other words, an audio signal must be broken up into spectrograms with the same number of time and frequency dimensions that the U-Net was trained with.
Output Signal Reconstruction
The neural network model operates exclusively on the magnitude of audio spectrograms. The audio signal for an individual (vocal/instrumental) component is rendered by constructing a spectrogram: the output magnitude is given by applying a mask predicted by the U-Net to the magnitude of the original spectrum, while the output phase is that of the original spectrum, unaltered.
The final mask is multiplied by the input mixture and the loss is taken between the ground truth source spectrogram and mixture spectrogram with the estimated mask applied, as per usual. Masking has many uses in different aspects of computer science and machine learning like language modeling and computer vision. It is also an essential part of how many modern source separation approaches approximate sources from a mixture. To separate a single source, a separation approach must create a single mask. To separate multiple sources, a separation approach must create multiple masks. A mask is a matrix that is the same size as a spectrogram and contains values in the inclusive interval [0.0,1.0]. Each value in the mask determines what proportion of energy of the original mixture a source contributes. In other words, for a particular bin in the spectrogram, a value of 1.0 will allow all of the sounds from the mixture through and a value of 0.0 will allow none of the sounds from the mixture through.
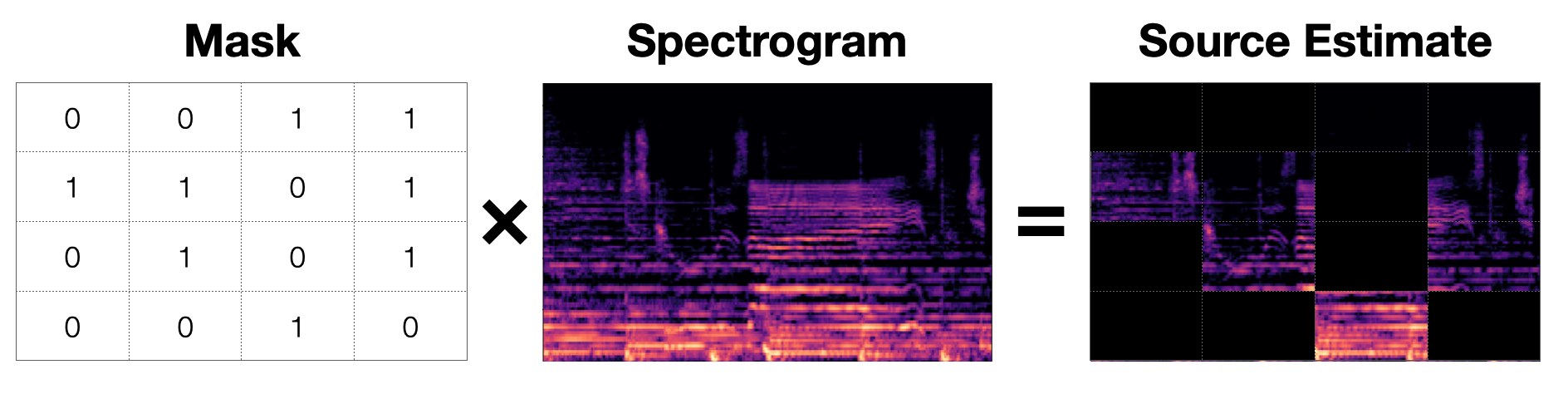
Fig. 3: A mask is a matrix with the same shape as the spectrogram that is element-wise multiplied by it to produce a source estimate. This image shows an exaggerated binary mask that produces a source estimate. Source: [1]
Sample Results
But how are the results? I tried a handful of tracks across multiple genres, and almost all of them performed incredibly well compared to other solutions. To avoid copyright infringement issues, I will just provide 30-second samples of each song (except the last Persian song). Below are the original, instrumental, and vocal versions of four samples I ran through the two-stem (instrumental/vocal) filter.
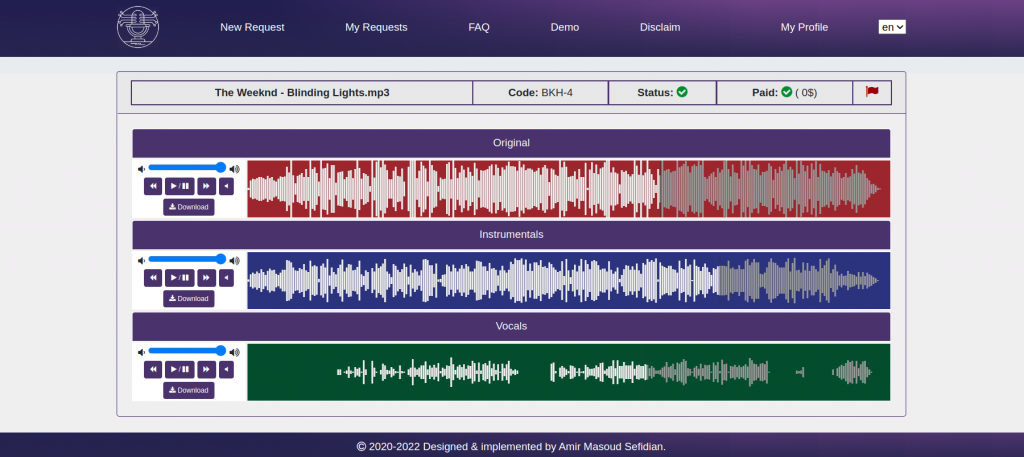
Sample 1) The Weekend – Blinding Lights
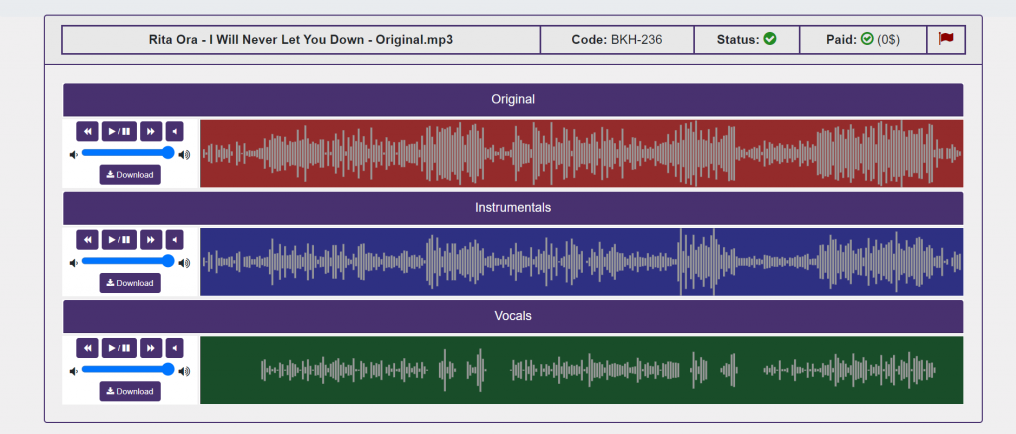
Sample 2) Rita Ora – I Will Never Let You Down
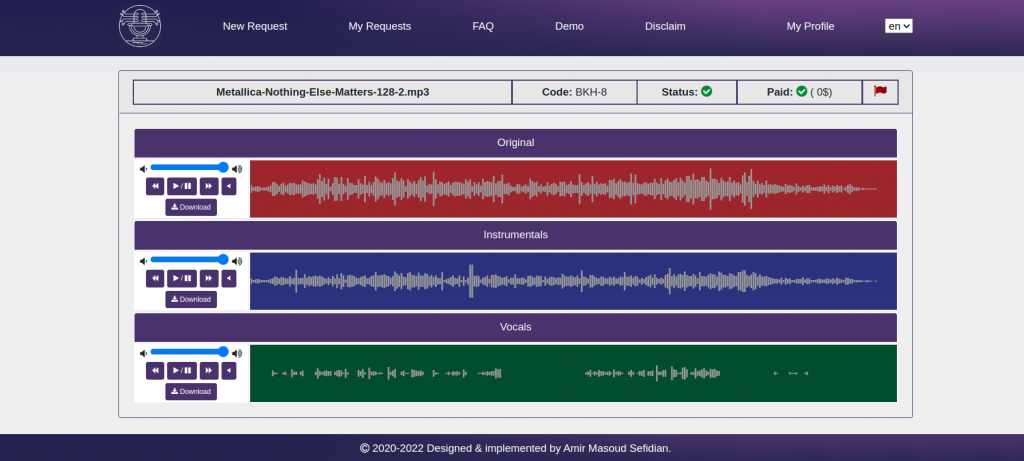
Sample 3) Metalica – Nothing Else Matters
Sample 4) Meysam Ebrahimi (Full Song) – You and I (Persian Song)
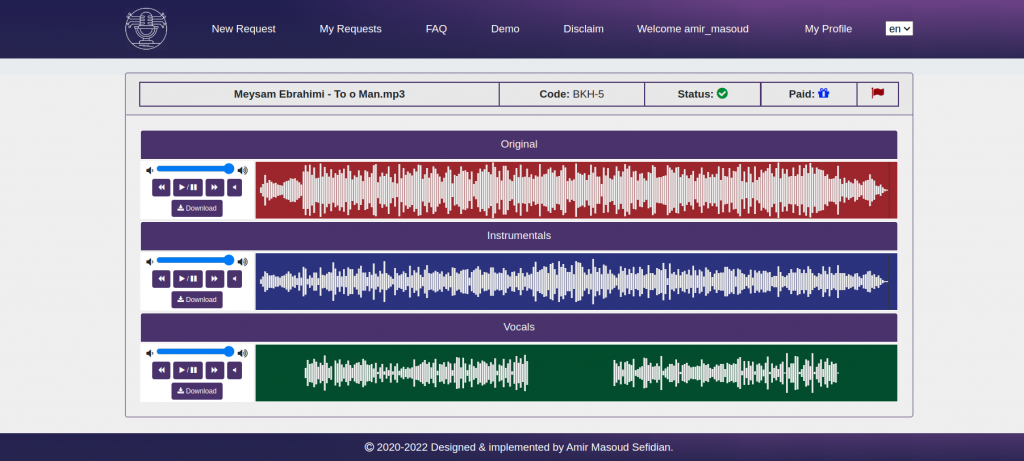
As you can see in the waveforms, the vocals waveform is perfectly isolated at spans that there is no vocal in the original song. Moreover, the system generated acceptable results regardless of the amplitude of original songs.
Other Features
I have designed a simple web application for my source separation system. Users can easily upload and separate a song into high-quality audio stems in less than a minute (on GeForce 960M). I used the Django framework to provide admin and client dashboards. The Flask was used to deploy the deep learning models. It provides a REST API for audio separation requests.
Some of the features of this web application are listed below:
- User authentication with different access levels
- Payment system
- Offering free and preview (a small portion of a song for checking the quality) separation results to users
- Waveform representation of original and isolated signals
- Users can submit their feedback on separation performance
Here are some screenshots of my audio separation web application. Please don’t blame me for the basic and unattractive design 😉 I am not a UI/UX designer or a front-end developer! This is just a prototype for testing the functionalities.
Conclusion
Splitting a song into separate vocals and instruments has always been a headache for producers, DJs, and anyone else who wants to play around with isolated audio. There are lots of ways to do it but the process can be time-consuming and the results are often imperfect. In this post, I introduced my AI-based vocal remover system that makes this tricky task faster and easier. I’m truly excited about how AI technologies are paving the way for music production. I’m extremely proud of this product and I hope users enjoy using it as much as I enjoyed creating it! Please feel free to contact me if you have any questions or if you want to test the performance of this system on your favorite song!