
Bulk Boto3 (bulkboto3): Python package for fast and parallel transferring a bulk of files to S3 based on boto3!
2022-03-28Understanding Factorized Top-K (FactorizedTopK) metric for recommendation systems with example
2022-04-30
MinIO is a high-performance object storage solution with native support for Kubernetes deployments that provides an Amazon Web Services S3-compatible API and supports all core S3 features. In this post, I will explain steps to deploy MinIO in Standalone Mode consisting of a single MinIO server and a single drive or storage volume on Linux using Docker Compose. Standalone deployments are best suited for evaluation and initial development environments. For extended development or production environments please refer to the official documentation Deploy MinIO in Distributed Mode.
Prerequisites
- Docker is installed on your machine. Download the relevant installer from here.
- Familiarity with Docker Compose.
Steps
1) Create a docker-compose YAML file called minio-compose.yml (or any name you want) in your current working directory and put the following scripts in this file.
MINIO_ROOT_USER and MINIO_ROOT_PASSWORD are two important environment variables in the docker-compose file. MINIO_ROOT_USER is the root user access key and MINIO_ROOT_PASSWORD is the root user secret key as your S3 credentials. Replace these values with long, random, and unique strings. Please note that there are two port numbers when you run the MinIO server:
a) The MinIO Console port has 9001 as its default value.
b) The API port, for connecting to and performing operations on the MinIO through APIs, which I set to a static port number 9000 in the docker-compose file.
You can change port mappings in the ports section of the docker-compose file.
Note: By default, the Docker Compose file uses the Docker image for the latest MinIO server release. You can change the image tag to pull a specific MinIO Docker image.
2) Run the compose using the following command (Add -d flag for running in docker detach mode).
docker-compose --project-name standalone_minio -f minio-compose.yml up
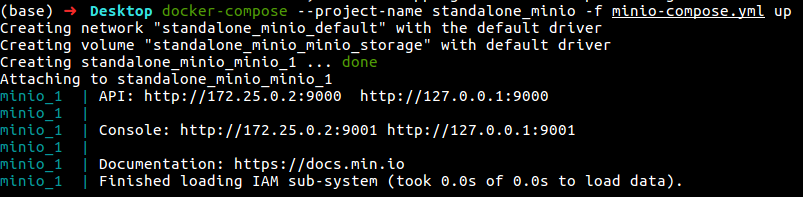
As I said in the previous step and as you can see in the above figure, our deployment would respond to S3 API operations on the default MinIO server port :9000 and browser access on the MinIO Console port :9001.
3) Access MinIO Console
Now you can access MinIO Console. Open your browser and go to http://127.0.0.1:9001 to open the MinIO Console login page.
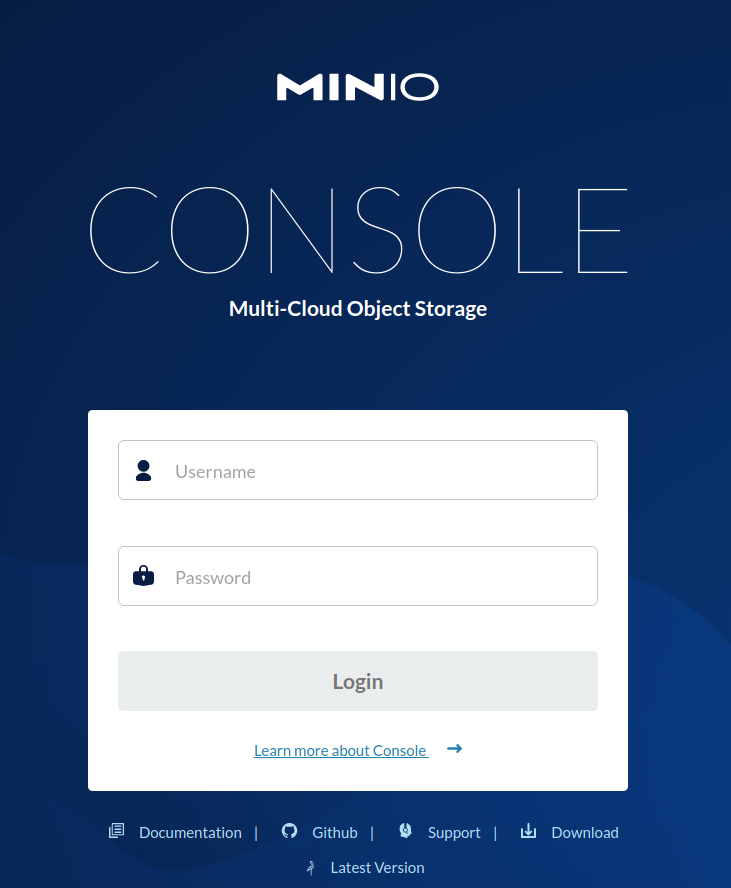
Log in with the Root User and Root Pass from the previous step.
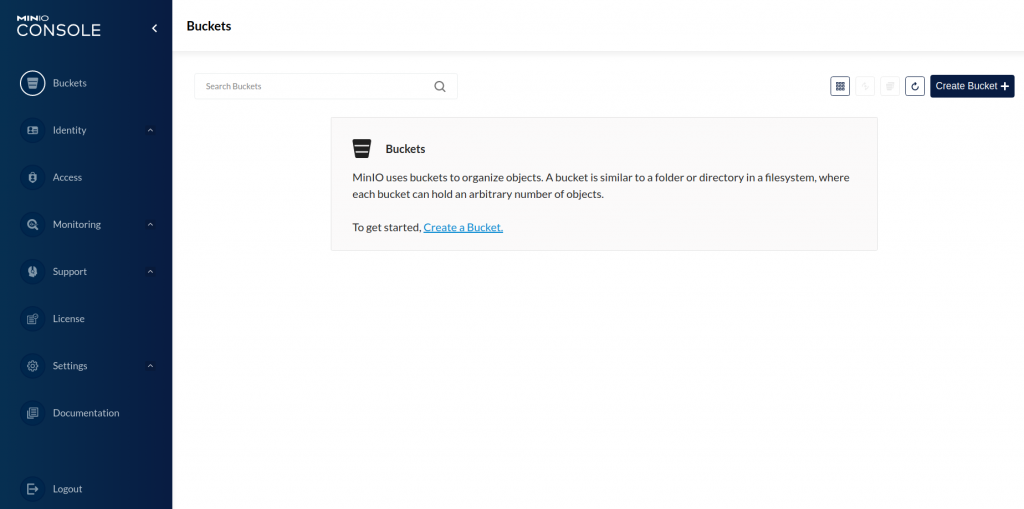
4) Access MinIO using API
In addition to the MinIO web console, you can use the API addresses to access the MinIO server and perform S3 operations. You can use different SDKs, such as boto3 and bulkboto3, to perform bucket and object operations to any Amazon S3-compatible object storage service. Applications can authenticate using the MINIO_ROOT_USER as aws_access_key_id and MINIO_ROOT_PASSWORD as aws_secret_access_key credentials. Please note that we need to communicate on port 9000 through MinIO APIs as we set in the docker-compose file. Here, I have provided a small python code for creating and transferring a directory with its structure to the bucket using the bulkboto3 package:
import logging
from bulkboto3 import BulkBoto3
logging.basicConfig(
level="INFO",
format="%(asctime)s — %(levelname)s — %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
)
logger = logging.getLogger(__name__)
TARGET_BUCKET = "test-bucket"
NUM_TRANSFER_THREADS = 50
TRANSFER_VERBOSITY = True
# instantiate a BulkBoto3 object
bulkboto_agent = BulkBoto3(
resource_type="s3",
endpoint_url="http://127.0.0.1:9000",
aws_access_key_id="masoud",
aws_secret_access_key="Strong#Pass#2022",
max_pool_connections=300,
verbose=TRANSFER_VERBOSITY,
)
# create a new bucket
bulkboto_agent.create_new_bucket(bucket_name=TARGET_BUCKET)
# upload a whole directory with its structure to an S3 bucket in multi thread mode
bulkboto_agent.upload_dir_to_storage(
bucket_name=TARGET_BUCKET,
local_dir="test_dir",
storage_dir="my_storage_dir",
n_threads=NUM_TRANSFER_THREADS,
)
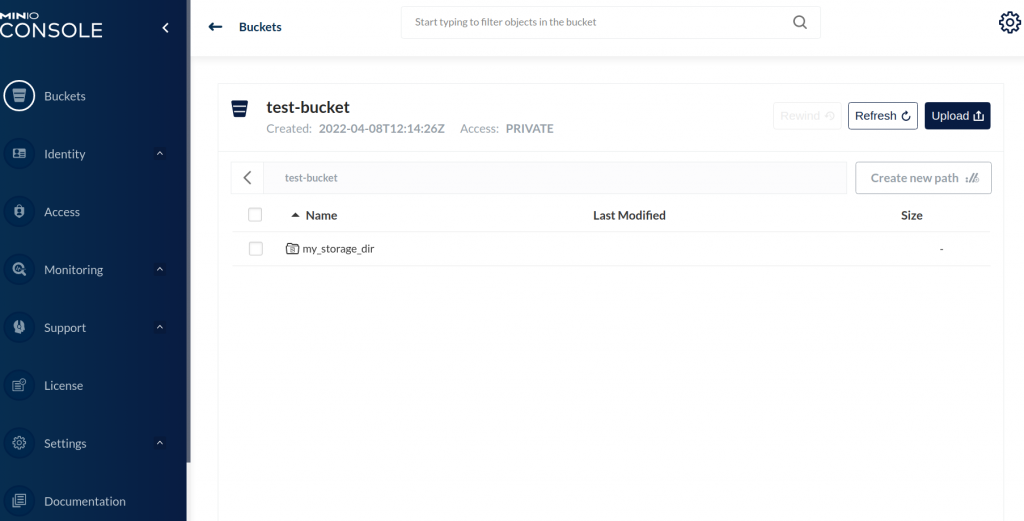
And here you can see the uploaded directory on the bucket!
You can find out more examples of S3 operations using APIs at the following links:
https://pypi.org/project/bulkboto3/
https://github.com/iamirmasoud/bulkboto3
BulkBoto3: Python package for fast and parallel transferring a bulk of files to S3 based on boto3!
Thank you for taking the time to this post. Stay tuned for the next posts!

{kind=link}
2 Comments
[…] Note: You can deploy a free S3 server using MinIO on your local machine by following steps explained in: Deploy Standalone MinIO using Docker Compose on Linux. […]
[…] provides an Amazon Web Services S3-compatible API and supports all core S3 features. Please see this tutorial to find out more details about MinIO standalone deployment. If you plan on sharing the same […]