
Audio source separation (vocal remover) system based on Deep Learning
2022-08-01A guide on regression error metrics (MSE, RMSE, MAE, MAPE, sMAPE, MPE) with Python code
2022-08-18A tutorial on Apache Cassandra data modeling – RowKeys, Columns, Keyspaces, Tables, and Keys

In this post, I will discuss the basic concepts of data modeling in Apache Cassandra. It is important to understand those concepts as they will help us to design an efficient system using Cassandra. I am assuming that you have installed Cassandra with CQL. You can download Cassandra from Apache Cassandra website. CQL 3.0 is the language that helps to work with Cassandra objects same as SQL language helps to work with SQL objects.
RowKeys:
We are all familiar with the map data structure. The map data structure is a list of key/value pairs in which we assign values against keys. Suppose we have a person’s profile with fields such as First Name (fname), Last Name(lname), DateOfBirth(dateofbirth), email address(email), and phone(phone). We can store this information in a map structure as shown in figure 1.

We can use a unique number to point to this map. We will call this unique number as a row key as shown in figure 2:

Similarly, we can view other person profiles in map structures and refer to them using unique row keys as shown in figure 3:

Note that the maps in figure 3 do not have all the key/value pairs as in figure 2. For example, the person profile for Adam Jones has key/value pairs: fname, lname, and dateofbirth. It does not have key/value pairs for phone number and email address. Similarly, the person profile Richard Douglas has three columns: fname, lname, and email. It does not have dateofbirth and phone key/value pairs. This is a common scenario in normal life where we have different information available for different persons. Suppose we are collecting this information for a census in a city. In that case, it makes sense to group those person profiles in a structure for processing and reporting. One way to group those data would be to introduce a two-dimensional map. In that two-dimensional map, the first dimension is the map in which keys are unique row keys and the values are the pointers to the map structure of the person profiles. The second dimension is the map structure which contains key/value pairs of person profile information. This is shown in figure 5:

In the above diagram, we have a map of row keys that point to person profile maps. For example row key 789 points to a person profile map of Adam Jones.
The two-dimensional map structure which we have just discussed will help us understand the concepts of tables, rows, and columns in Cassandra. Before moving forward I would suggest running Cassandra so that you can run CQL statements on your machine. Open a command terminal and using cd command go to the directory where Cassandra is installed. Run the following command in the terminal window:
bin/cassandra -f
This will run Cassandra application which resides in the bin folder of Cassandra installation. Open another terminal tab or window and while Cassandra is running, start the Cassandra command line interface by typing the following command.
bin/cqlsh
After cqlsh has launched successfully, you will see cqlsh command prompt. We will type all the CQL commands in cqlsh interface.
Keyspaces:
The concept of keyspace is somewhat similar to creating a database in a SQL database. A keyspace is a namespace that defines how data is replicated on nodes. At the moment we will not go into details of replication but for our purpose, it is important to understand that the keyspace is a container and contains several tables. We can create a keyspace named census with the following command:
create keyspace census with replication = {'class' : 'SimpleStrategy', 'replication_factor':1};
With this, we create a keyspace called census with some replication policies. We will discuss replication policies in later posts. After the keyspace is set successfully you can set it as the current keyspace by typing the following command in cqlsh terminal window:
use census;
Tables:
In Cassandra, a table can have a number of rows. Each row is referenced by a primary key called row key. There is a number of columns in a row but the number of columns can vary in different rows. For example, one row in a table can have three columns whereas the other row in the same table can have ten columns. It is also important to note that in Cassandra both column names and values have binary types. This means column names can have binary values such as string, timestamp, an integer, etc. This is different from SQL databases where each row in an SQL table has a fixed number of columns and column names can only be text.
Now we will create a person profile table which we have discussed before. Go to the cqlsh terminal window and type the following command. Make sure that your current keyspace is census. A person table can be created using CQL 3.0 in keyspace Census as follows:
create table person ( person_id int primary key, fname text, lname text, dateofbirth timestamp, email text, phone text );
In the above statement, we have created a table person which has a person_id column as a primary key. The primary key is the same as a rowkey which we have mentioned before. The person table has a few other columns such as fname, lname, dateofbirth, email, and phone. If you have worked with SQL databases then the above create statement will look familiar. Next, we will insert some data and see how they are stored in the database. Type the following command on cqlsh terminal window:
insert into person (person_id, fname, lname, dateofbirth, email, phone)
values ( 123, 'Chris', 'Williams', '1960-05-20', 'chris.williams@test.com', '099045769');
The above statement will insert Chris Williams person profile into the database. We can check if the data has been added successfully by using the select statement. Type the following command in cqlsh terminal window:
select * from person;
The output is:
person_id | dateofbirth | email | fname | lname | phone
-----------+--------------------------+-------------------------+-------+----------+-----------
123 | 1960-05-20 00:00:00-0400 | chris.williams@test.com | Chris | Williams | 099045769
We can see that the information is the same as we inserted using the insert statement. Note that the syntax of insert and select statements are similar to SQL database. At this point, you may find it difficult to relate the output of the select statement to the map structure concept which we have discussed before. With the cqlsh interface, we do not really see how data is stored in the database. But you can see the relation by using another tool called cassandra-cli. cassandra-cli tool comes with the standard Cassandra installation so you do not need to install any additional software. This tool resides in the bin folder along with the cassandra and cqlsh executables. This tool is useful to see how data is stored in the Cassandra system. Open another terminal tab or window and run the following command:
bin/cassandra-cli
When this application is launched you will see a command prompt. On this command prompt type:
use census;
This is the same statement that we used on cqlsh prompt to select the keyspace. We have already created census keyspace so the application should successfully switch to that keyspace. We will now access the person table to see the records in that table. Type the following command on cassandra-cli command prompt.
list person;
RowKey: 123
=> (name=, value=, timestamp=1384058627117000)
=> (name=dateofbirth, value=ffffffb955773e00, timestamp=1384058627117000)
=> (name=email, value=63687269732e77696c6c69616d7340746573742e636f6d, timestamp=1384058627117000)
=> (name=fname, value=4368726973, timestamp=1384058627117000)
=> (name=lname, value=57696c6c69616d73, timestamp=1384058627117000)
=> (name=phone, value=303939303435373639, timestamp=1384058627117000)
As we can see that the value of the primary key column i.e person_id has become RowKey. The value of person_id is 123. This row has several columns. The first column has no name and value. This column represents the Rowkey or primary_key. If you look at the above output carefully you will notice that the name of the primary key column i.e. person_id is missing. The column name of rowkey or primary key is stored in another table which we will discuss later in this article. The missing column name and value are useful for a case when the table has only one column. But at the moment this is not important to understand the concept of data modeling so we will skip it. The second column has name: dateofbirth and value: ffffffb955773e00. The value is the binary representation of the date which we entered i.e. ‘1960-05-20’. Similarly email has value 63687269732e77696c6c69616d7340746573742e636f6d which is binary representation of chris.williams@test.com. This is the same for other columns and values. Note that each column has a timestamp value. The timestamp value represents the time when the values were added to the database.
If you compare the above output with the map structure which we have discussed before you will find that they are similar. In the map structure, each row is represented by the rowkey and it has a number of key/value pairs. The above row output also has rowkey and column name/value pairs. It also has an additional field of timestamp. In the map structure, we mentioned that different rows can have different numbers of columns. To check how it works in Cassandra we will insert another row with less number of columns. Type the following command on cqlsh command-line interface. Please note that it is cqlsh and not cassandra-cli prompt.
insert into person ( person_id, fname, lname,dateofbirth)
values ( 456, 'Adam', 'Jones', '11985-04-18');
We now retrieve the data by using the select statement.
select * from person;
person_id | dateofbirth | email | fname | lname | phone
-----------+---------------------------+-------------------------+-------+----------+-----------
123 | 1960-05-20 00:00:00-0400 | chris.williams@test.com | Chris | Williams | 099045769
456 | 11985-04-17 23:00:00-0500 | null | Adam | Jones | null
The first row person_id 123 contains all the columns whereas the second row person_id 456 has only four columns: person_id, dateofbirth, fname, and lname. The row person_id 456 does not have email and phone number columns. The value of email and phone number for person_id 456 is shown as null in the output of the select statement. You now wonder how it is different from SQL database where if a column value does not exist then it is set to null. We see how it is represented under the hood using cassandra-cli. Type the following command in cassandra-cli interface.
list person;
RowKey: 123
=> (name=, value=, timestamp=1384058627117000)
=> (name=dateofbirth, value=ffffffb955773e00, timestamp=1384058627117000)
=> (name=email, value=63687269732e77696c6c69616d7340746573742e636f6d, timestamp=1384058627117000)
=> (name=fname, value=4368726973, timestamp=1384058627117000)
=> (name=lname, value=57696c6c69616d73, timestamp=1384058627117000)
=> (name=phone, value=303939303435373639, timestamp=1384058627117000)
-------------------
RowKey: 456
=> (name=, value=, timestamp=1384112124419000)
=> (name=dateofbirth, value=00011f72a1036e00, timestamp=1384112124419000)
=> (name=fname, value=4164616d, timestamp=1384112124419000)
=> (name=lname, value=4a6f6e6573, timestamp=1384112124419000)
It returns two rows. The first row is RowKey 123 which we have discussed before. The second row is RowKey 456. The RowKey 456 has one primary key column which has an empty name and value. The other columns are dateofbirth, fname, and lname. Notice that it does not store column name/value pairs for email and phone number as they do not exist for this row. This means that the null values which we saw in cqlsh command interface are only for display purposes. The table does not store null values for columns that are not present in the system.
Primary key names:
As we mentioned before that the value of the primary key is not displayed when we use list person command. These values are stored in the schema_columnfamilies table in the keyspace called system. system keyspace is managed by Cassandra and we do not need to create this keyspace.
Type the following command in cqlsh interface:
SELECT key_aliases, column_aliases FROM system.schema_columnfamilies
WHERE keyspace_name='census' AND columnfamily_name='person';
The output will be:
key_aliases | column_aliases
---------------+----------------
["person_id"] | []
The key alias column contains values for the primary key.
The rows in Cassandra are stored in the form of variable key/value pairs or columns. We also observed that each row in a table is referenced by a primary key or a row key. The primary key concept in Cassandra is different from Relational databases. Therefore it is worth spending time to understand this concept.
We created a person table that had a person_id as a primary key column.
create table person (person_id int primary key, fname text, lname text, dateofbirth timestamp, email text, phone text );
We saw that the person_id was used as a row key to refer to person data.
Compound (Composite) primary key:
As the name suggests, the compound primary key is comprised of one or more columns that are referenced in the primary key. One component of the compound primary key is called the partition key whereas the other component is called the clustering key. Following are different variations of primary keys. Please note that K1, K2, K3,… and so on represent columns in the table.
- K1: primary key has only one partition key and no cluster key.
- (K1, K2): column K1 is a partition key and column K2 is a cluster key.
- (K1, K2, K3, …): column K1 is a partition key and columns K2, K3 and so on make clustering key.
- (K1, (K2, K3, …)): It is the same as 3 i.e column K1 is a partition key and columns K2, K3, … make clustering key.
- ((K1, K2, …), (K3, K4, …)): columns K1, K2 make partition key and columns K3, K4, … make clustering key.
It is important to note that when the compound key is K1, K2, and K3 then the first key K1 becomes the partition key, and the rest of the keys become part of the cluster key. In order to make composite partition keys we have to specify keys in parenthesis such as: (( K1, K2), K3, K4). In this case, K1 and K2 are part of the partition keys, and K3 and K4 are part of the cluster key.
Partition key
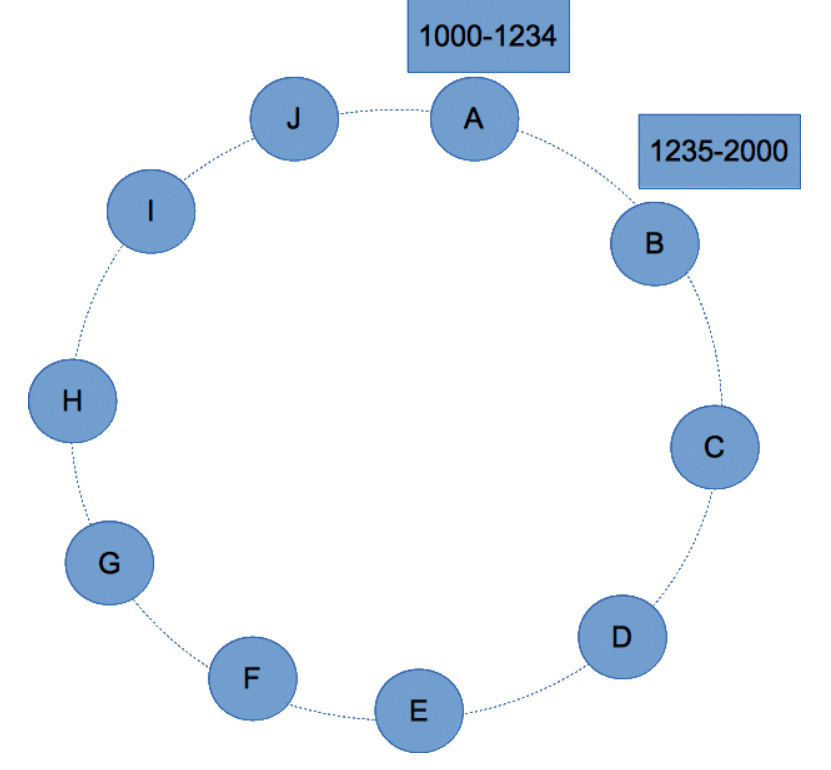
The purpose of the partition key is to identify the partition or node in the cluster which stores that row. When data is read or written from the cluster a function called Partitioner is used to compute the hash value of the partition key. This hash value is used to determine the node/partition which contains that row. For example, rows whose partition key values range from 1000 to 1234 may reside in node A and rows with partition key values range from 1235 to 2000 may reside in node B as shown in figure 6. If a row contains a partition key whose hash value is 1233 then it will be stored in node A.
Clustering key
The purpose of the clustering key is to store row data in sorted order. The sorting of data is based on columns that are included in the clustering key. This arrangement makes it efficient to retrieve data using the clustering key.
To make these concepts clear we will consider an example of a weather forecast system. The purpose of this system is to store weather-related data. First, we will create a weather keyspace using cqlsh. Type the following command on cqlsh terminal window:
create keyspace weather with replication = {'class' : 'SimpleStrategy', 'replication_factor':1};
This creates weather keyspace with replication strategy ‘SimpleStrategy’ and replication_factor 1.
Now switch to weather keyspace:
use weather;
We will create a table city that contains general weather information about that city. Type the following create statement into cqlsh.
create table city (cityid int, avg_tmp float, description text, primary key (cityid));
The above statement will create a table city with primary key cityid. As there is only one column in the primary key therefore the partition key would be cityid and there will be no clustering key.
Type the following insert statements to enter some data into this table.
insert into city (cityid, avg_tmp, description) values (1,25.5,'Mild weather');
insert into city (cityid, avg_tmp, description) values (2,3,'Cold weather');
Check the data which we have just inserted into the table.
select * from city;
The output would be as follows:
cityid | avg_tmp | description
--------+---------+--------------
1 | 25.5 | Mild weather
2 | 3 | Cold weather
We can see how Cassandra has stored this data under the hood by using cassandra-cli tool. Run cassandra-cli tool in a separate terminal window and type the following command on that terminal.
use weather;
list city;
RowKey: 1
=> (name=, value=, timestamp=1387128357537000)
=> (name=avg_tmp, value=41cc0000, timestamp=1387128357537000)
=> (name=description, value=4d696c642077656174686572, timestamp=1387128357537000)
-------------------
RowKey: 2
=> (name=, value=, timestamp=1387128377816000)
=> (name=avg_tmp, value=40400000, timestamp=1387128377816000)
=> (name=description, value=436f6c642077656174686572, timestamp=1387128377816000)
2 Rows Returned.
Elapsed time: 163 msec(s).
We can see from the above output that the cityid has become the row key and it identifies individual rows. We can use columns in the primary key to filter data in the select statement. Type the following command in the cqlsh window:
select * from city where cityid = 1;
We get the following output:
cityid | avg_tmp | description
--------+---------+--------------
1 | 25.5 | Mild weather
Now we will create another table called forecast which records the temperature of each city every day. Type the following command on cqlsh:
create table forecast(cityid int, forecast_date timestamp, humidity float, chanceofrain float,wind float, feelslike int, centigrade int, primary key (cityid, forecast_date));
This statement creates a forecast table with the primary key ( city id, forecast_date). As the primary key has two components therefore the first component is considered as partition key (cityid) and the second component becomes the clustering key (forecast_date). Add some data to the table:
insert into forecast(cityid,forecast_date,humidity,chanceofrain,wind,feelslike,centigrade) values (1,'2013-12-10',0.76,0.1,10,8,8);
insert into forecast(cityid,forecast_date,humidity,chanceofrain,wind,feelslike,centigrade) values (1,'2013-12-11',0.90,0.3,12,4,4);
insert into forecast(cityid,forecast_date,humidity,chanceofrain,wind,feelslike,centigrade) values (1,'2013-12-12',0.68,0.2,6,3,3);
Notice that in this case values of the partition key i.e cityid are the same but the values of the clustering key i.e forcast_date are different. Now retrieve this data from the table.
select * from forecast;
We get the following output:
cityid | forecast_date | centigrade | chanceofrain | feelslike | humidity | wind
--------+--------------------------+------------+--------------+-----------+----------+------
1 | 2013-12-10 00:00:00+0000 | 8 | 0.1 | 8 | 0.76 | 10
1 | 2013-12-11 00:00:00+0000 | 4 | 0.3 | 4 | 0.9 | 12
1 | 2013-12-12 00:00:00+0000 | 3 | 0.2 | 3 | 0.68 | 6
As expected we get three rows with all rows having the same partition key values but different clustering key values. Let’s check what it looks like in cassandra-cli. Go to cassandra cli and type the following command:
list forecast;
It displays the following output:
RowKey: 1
=> (name=2013-12-10 00\:00\:00+0000:, value=, timestamp=1386700252831000)
=> (name=2013-12-10 00\:00\:00+0000:centigrade, value=00000008, timestamp=1386700252831000)
=> (name=2013-12-10 00\:00\:00+0000:chanceofrain, value=3dcccccd, timestamp=1386700252831000)
=> (name=2013-12-10 00\:00\:00+0000:feelslike, value=00000008, timestamp=1386700252831000)
=> (name=2013-12-10 00\:00\:00+0000:humidity, value=3f428f5c, timestamp=1386700252831000)
=> (name=2013-12-10 00\:00\:00+0000:wind, value=41200000, timestamp=1386700252831000)
=> (name=2013-12-11 00\:00\:00+0000:, value=, timestamp=1386700252835000)
=> (name=2013-12-11 00\:00\:00+0000:centigrade, value=00000004, timestamp=1386700252835000)
=> (name=2013-12-11 00\:00\:00+0000:chanceofrain, value=3e99999a, timestamp=1386700252835000)
=> (name=2013-12-11 00\:00\:00+0000:feelslike, value=00000004, timestamp=1386700252835000)
=> (name=2013-12-11 00\:00\:00+0000:humidity, value=3f666666, timestamp=1386700252835000)
=> (name=2013-12-11 00\:00\:00+0000:wind, value=41400000, timestamp=1386700252835000)
=> (name=2013-12-12 00\:00\:00+0000:, value=, timestamp=1386700255855000)
=> (name=2013-12-12 00\:00\:00+0000:centigrade, value=00000003, timestamp=1386700255855000)
=> (name=2013-12-12 00\:00\:00+0000:chanceofrain, value=3e4ccccd, timestamp=1386700255855000)
=> (name=2013-12-12 00\:00\:00+0000:feelslike, value=00000003, timestamp=1386700255855000)
=> (name=2013-12-12 00\:00\:00+0000:humidity, value=3f2e147b, timestamp=1386700255855000)
=> (name=2013-12-12 00\:00\:00+0000:wind, value=40c00000, timestamp=1386700255855000)
1 Row Returned.
Elapsed time: 200 msec(s).
We can see from the output that cassandra-cli has returned only one row instead of three rows as returned by cqlsh. The reason is that Cassandra stores only one row for each partition key. All the data associated with that partition key is stored as columns in the datastore. The data which we have stored through three different insert statements have the same cityid value i.e. 1 therefore all the data is saved in that row as columns.
If you remember we discussed before that the second component of a primary key is called clustering key. The role of the clustering key is to group related items together. All the data which is inserted against the same clustering key are grouped together. Let’s see how it is done? If you recall the first insert statement which we have issued is as follows:
insert into forecast(cityid, forecast_date, humidity, chanceofrain, wind, feelslike, centigrade)
values (1,'2013-12-10',0.76,0.1,10,8,8);
In this case, all the columns such as humidity, chainceofrain, wind, feelslike, and centigrade will be grouped by value in forecast_date i.e 2013-12-10 00\:00\:00+0000. If we look at the output of cassandra-cli we see that the first five columns names have 2013-12-10 00\:00\:00+0000 as shown below:
=> (name=2013-12-10 00\:00\:00+0000:, value=, timestamp=1386700252831000)
=> (name=2013-12-10 00\:00\:00+0000:centigrade, value=00000008, timestamp=1386700252831000)
=> (name=2013-12-10 00\:00\:00+0000:chanceofrain, value=3dcccccd, timestamp=1386700252831000)
=> (name=2013-12-10 00\:00\:00+0000:feelslike, value=00000008, timestamp=1386700252831000)
=> (name=2013-12-10 00\:00\:00+0000:humidity, value=3f428f5c, timestamp=1386700252831000)
=> (name=2013-12-10 00\:00\:00+0000:wind, value=41200000, timestamp=1386700252831000)
In the above output, the first column name is 2013-12-10 00\:00\:00+0000 which represents the clustering key. Note that this column does not have any key value. The value of the column is already stored in the column name. It is important to remember that in Cassandra column names can be of any binary type which is different from Relational databases where column names can only be text. The second column is: 2013-12-10 00\:00\:00+0000:centigrade. Its value is 00000008. Note that the forecast_date value has been appended in the column name. This is the same with all the other columns which correspond to 2013-12-10 00\:00\:00+0000. Similarly, different values of forecast_dates are appended to other columns as shown below:
=> (name=2013-12-11 00\:00\:00+0000:, value=, timestamp=1386700252835000)
=> (name=2013-12-11 00\:00\:00+0000:centigrade, value=00000004, timestamp=1386700252835000)
=> (name=2013-12-11 00\:00\:00+0000:chanceofrain, value=3e99999a, timestamp=1386700252835000)
=> (name=2013-12-11 00\:00\:00+0000:feelslike, value=00000004, timestamp=1386700252835000)
=> (name=2013-12-11 00\:00\:00+0000:humidity, value=3f666666, timestamp=1386700252835000)
=> (name=2013-12-11 00\:00\:00+0000:wind, value=41400000, timestamp=1386700252835000)
=> (name=2013-12-12 00\:00\:00+0000:, value=, timestamp=1386700255855000)
=> (name=2013-12-12 00\:00\:00+0000:centigrade, value=00000003, timestamp=1386700255855000)
=> (name=2013-12-12 00\:00\:00+0000:chanceofrain, value=3e4ccccd, timestamp=1386700255855000)
=> (name=2013-12-12 00\:00\:00+0000:feelslike, value=00000003, timestamp=1386700255855000)
=> (name=2013-12-12 00\:00\:00+0000:humidity, value=3f2e147b, timestamp=1386700255855000)
=> (name=2013-12-12 00\:00\:00+0000:wind, value=40c00000, timestamp=1386700255855000)
In the above output, columns that are associated with clustering key: 2013-12-11 00\:00\:00+000 have columns names starting with 2013-12-11 00\:00\:00+000. Similarly columns which are associated with clustering key: 2013-12-12 00\:00\:00+0000 have column names starting with 2013-12-12 00\:00\:00+0000. As there are three different clustering key values therefore we get three rows when we run the select statement in cqlsh.
Suppose that the city is very big and we want to store weather forecast separately for each region/town in that city. One option could be to define a composite partition key that is composed of cityid and regionid. In that case, rowkey would be city id and region id. Let’s create this table into the weather keyspace using cqlsh.
create table forecast_for_region(cityid int, regionid int, forecast_date timestamp, humidity float, chanceofrain float, wind float, feelslike int, centigrade int, primary key ((cityid, regionid), forecast_date));
Now insert some data into the table:
insert into forecast_for_region(cityid,regionid,forecast_date,humidity,chanceofrain,wind,feelslike,centigrade) values (1,24, '2013-12-10',0.76,0.1,10,8,8);
insert into forecast_for_region(cityid,regionid,forecast_date,humidity,chanceofrain,wind,feelslike,centigrade) values (1,24,'2013-12-11',0.90,0.3,12,4,4);
insert into forecast_for_region(cityid,regionid,forecast_date,humidity,chanceofrain,wind,feelslike,centigrade) values (1,24,'2013-12-12',0.68,0.2,6,3,3);
Check the data in cqlsh using the select statement:
select * from forecast_for_region;
The output would be as follows:
cityid | regionid | forecast_date | centigrade | chanceofrain | feelslike | humidity | wind
--------+----------+--------------------------+------------+--------------+-----------+----------+------
1 | 24 | 2013-12-10 00:00:00+0000 | 8 | 0.1 | 8 | 0.76 | 10
1 | 24 | 2013-12-11 00:00:00+0000 | 4 | 0.3 | 4 | 0.9 | 12
1 | 24 | 2013-12-12 00:00:00+0000 | 3 | 0.2 | 3 | 0.68 | 6
Check the output in cassandra-cli:
list forecast_for_region;
RowKey: 1:24
=> (name=2013-12-10 00\:00\:00+0000:, value=, timestamp=1386777901856000)
=> (name=2013-12-10 00\:00\:00+0000:centigrade, value=00000008, timestamp=1386777901856000)
=> (name=2013-12-10 00\:00\:00+0000:chanceofrain, value=3dcccccd, timestamp=1386777901856000)
=> (name=2013-12-10 00\:00\:00+0000:feelslike, value=00000008, timestamp=1386777901856000)
=> (name=2013-12-10 00\:00\:00+0000:humidity, value=3f428f5c, timestamp=1386777901856000)
=> (name=2013-12-10 00\:00\:00+0000:wind, value=41200000, timestamp=1386777901856000)
=> (name=2013-12-11 00\:00\:00+0000:, value=, timestamp=1386777901907000)
=> (name=2013-12-11 00\:00\:00+0000:centigrade, value=00000004, timestamp=1386777901907000)
=> (name=2013-12-11 00\:00\:00+0000:chanceofrain, value=3e99999a, timestamp=1386777901907000)
=> (name=2013-12-11 00\:00\:00+0000:feelslike, value=00000004, timestamp=1386777901907000)
=> (name=2013-12-11 00\:00\:00+0000:humidity, value=3f666666, timestamp=1386777901907000)
=> (name=2013-12-11 00\:00\:00+0000:wind, value=41400000, timestamp=1386777901907000)
=> (name=2013-12-12 00\:00\:00+0000:, value=, timestamp=1386777901911000)
=> (name=2013-12-12 00\:00\:00+0000:centigrade, value=00000003, timestamp=1386777901911000)
=> (name=2013-12-12 00\:00\:00+0000:chanceofrain, value=3e4ccccd, timestamp=1386777901911000)
=> (name=2013-12-12 00\:00\:00+0000:feelslike, value=00000003, timestamp=1386777901911000)
=> (name=2013-12-12 00\:00\:00+0000:humidity, value=3f2e147b, timestamp=1386777901911000)
=> (name=2013-12-12 00\:00\:00+0000:wind, value=40c00000, timestamp=1386777901911000)
1 Row Returned.
Elapsed time: 225 msec(s).
In the above output, we can see that the Row key is the combination of cityid and regionid. This means data for different regions within the same city can reside on different partitions or nodes in a cluster.
I hope these examples would have helped you to clarify a few concepts of data modeling in Cassandra.
Summary:
The primary key is a general concept to indicate one or more columns used to retrieve data from a Table.
The primary key may be SIMPLE and even declared inline:
create table stackoverflow_simple (
key text PRIMARY KEY,
data text
);
That means that it is made of a single column.
But the primary key can also be COMPOSITE (aka COMPOUND), generated from more columns.
create table stackoverflow_composite (
key_part_one text,
key_part_two int,
data text,
PRIMARY KEY(key_part_one, key_part_two)
);
In a situation of COMPOSITE primary key, the “first part” of the key is called PARTITION KEY (in this example key_part_one is the partition key) and the second part of the key is the CLUSTERING KEY (in this example key_part_two)
Please note that both partition and clustering keys can be made by more columns, here’s how:
create table stackoverflow_multiple (
k_part_one text,
k_part_two int,
k_clust_one text,
k_clust_two int,
k_clust_three uuid,
data text,
PRIMARY KEY((k_part_one, k_part_two), k_clust_one, k_clust_two, k_clust_three)
);
Behind these names …
- The Partition Key is responsible for data distribution across your nodes.
- The Clustering Key is responsible for data sorting within the partition.
- The Primary Key is equivalent to the Partition Key in a single-field-key table (i.e. Simple).
- The Composite/Compound Key is just any multiple-column key
Small usage and content examples
***SIMPLE*** KEY:
insert into stackoverflow_simple (key, data) VALUES ('han', 'solo');
select * from stackoverflow_simple where key='han';
table content
key | data
----+------
han | solo
COMPOSITE/COMPOUND KEY can retrieve “wide rows” (i.e. you can query by just the partition key, even if you have clustering keys defined)
insert into stackoverflow_composite (key_part_one, key_part_two, data) VALUES ('ronaldo', 9, 'football player');
insert into stackoverflow_composite (key_part_one, key_part_two, data) VALUES ('ronaldo', 10, 'ex-football player');
select * from stackoverflow_composite where key_part_one = 'ronaldo';
table content
key_part_one | key_part_two | data
--------------+--------------+--------------------
ronaldo | 9 | football player
ronaldo | 10 | ex-football player
But you can query with all keys (both partition and clustering) …
select * from stackoverflow_composite
where key_part_one = 'ronaldo' and key_part_two = 10;
query output
key_part_one | key_part_two | data
--------------+--------------+--------------------
ronaldo | 10 | ex-football player
Important note: the partition key is the minimum specifier needed to perform a query using a where clause. If you have a composite partition key, like the following
eg: PRIMARY KEY((col1, col2), col10, col4))
You can perform query only by bypassing at least both col1 and col2, these are the 2 columns that define the partition key. The “general” rule to make a query is you must pass at least all partition key columns, then you can add optionally each clustering key in the order they’re set.
so, the valid queries are (excluding secondary indexes)
- col1 and col2
- col1 and col2 and col10
- col1 and col2 and col10 and col 4
Invalid:
- col1 and col2 and col4
- anything that does not contain both col1 and col2
The terms “row” and “column” are used in the context of CQL, not how Cassandra is actually implemented.
- A primary key uniquely identifies a row.
- A composite key is a key formed from multiple columns.
- A partition key is a primary lookup to find a set of rows, i.e. a partition.
- A clustering key is the part of the primary key that isn’t the partition key (and defines the ordering within a partition).
Examples:
PRIMARY KEY (a): The partition key isa.PRIMARY KEY (a, b): The partition key isa, the clustering key isb.PRIMARY KEY ((a, b)): The composite partition key is(a, b).PRIMARY KEY (a, b, c): The partition key isa, the composite clustering key is(b, c).PRIMARY KEY ((a, b), c): The composite partition key is(a, b), the clustering key isc.PRIMARY KEY ((a, b), c, d): The composite partition key is(a, b), the composite clustering key is(c, d).

{kind=link}
{kind=link}