
How to return pandas dataframes from Scikit-Learn transformations: New API simplifies data preprocessing
2022-10-24Repository for implementation of statistics concepts for Data Science in Python
2022-11-16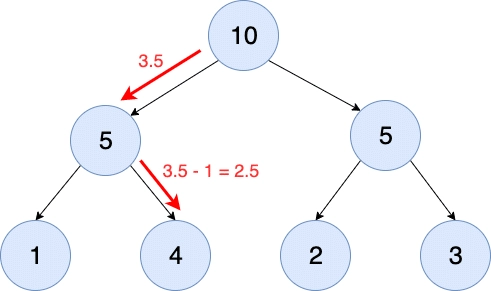
Weighted sampling from a list-like collection is an important activity in many applications. Weighted sampling involves selecting samples randomly from a collection, but where the “scales are tipped” towards those entries within the collection with a higher weighting. So an entry with a weight 4 times that of another entry gets sampled 4 times more frequently. Weighted sampling is required in particular in the Prioritised Experience Replay (PER) algorithm which is part of Q-based reinforcement learning. However, naive weighted sampling algorithms based on cumulative sums have poor performance when there are hundreds of thousands or millions of entries in the collection. Collections of this size often occur in Q-based reinforcement learning, and the PER algorithm which improves the performance of Q-based reinforcement learning requires weighted sampling. However, there is a more efficient data structure to perform weighted sampling, and this data structure is called the SumTree. This post will describe how SumTrees work and how to build them in Python. The code for this post can be found on this site’s Github repo.
Weighted sampling and sorting
Let’s say we have a tuple of entries in a list, something like this:
[(214, 1),
(342, 4),
(42, 2)
(123, 3)]
The first element in each tuple is the value you want to sample, and the second element in the tuple is the weighting value which governs the frequency that each element is randomly sampled. In the example above, we would expect the 342 value to be sampled 4 times as frequently as the 214 value. How would we perform this weighted sampling? A straightforward way is to perform a cumulative sum, then perform sampling based on a uniform probability distribution.
Here is the same collection but with a cumulative sum “column” added:
[(214, 1, 1),
(342, 4, 5),
(42, 2, 7),
(123, 3, 10)]
To perform weighted sampling, once cumulative summing is performed, one can sample from a uniform distribution with a minimum of 0 and a maximum of 10 (the highest value in the cumulative sum) and sample the element which has a cumulative interval corresponding to the sample from the uniform distribution. For instance, if the random number extracted from the uniform distribution U(0, 10) is 0.5, then the first element in the sorted list would be sampled (value = 214). If the random number instead was 7.8, the sampled value would be 123.
As can be observed, the element with a weight = 4 takes up 40% of the total interval between 0 and 10, as opposed to only 10% of the element with a weight = 1. Therefore, sampling using this method will respect the weight values and proportion them accordingly.
So far so good. However, what happens if our collection is millions of entries long? This method has a time complexity of $O(n)$ during the sampling process – which means that the time it takes to sample an entry is proportional to the number of elements in the collection. Therefore, for collections with millions of entries, the computational cost of this method, given frequent sampling, can be significant. The SumTree algorithm/data structure can do better – its time complexity if $O(log n)$ which is significantly quicker.
Introduction to the SumTree
The diagram below shows the SumTree for the collection shown above:
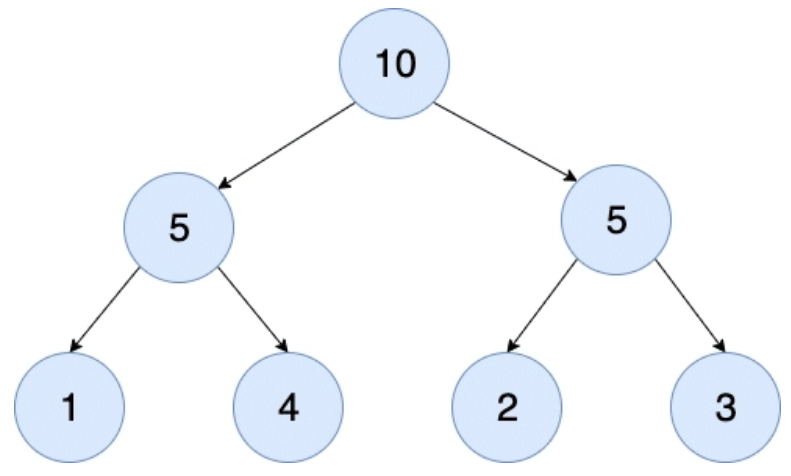
The first thing to note is that the “leaf” nodes of the tree (1, 4, 2, 3) correspond to the weights of the collection previously shown. The next thing to note is that the parents of each leaf node have a value equal to the sum of its children. So, for instance, the parent node of the 1 and 4 value leaf nodes has a value of 5. Likewise for the other parent node, and then the same summation occurs to produce the value for the top value of the tree (10).
How does the data extraction work from such a tree? The top parent node in a SumTree has a value equal to the summation of all the leaf nodes of the tree. So the first step is to perform a uniform random sampling of a value between 0 and the value of the top-parent (i.e. in this case U(0, 10)). Let’s say this sampled value, in this case, is 3.5. Let’s assign this to a variable named value. The first retrieval step is to see if value is less than the left-hand child node. When this occurs we keep value the same and traverse to the left-hand child. Next, we do the same comparison – is value less than the left-hand child node (is value < 1)? In this case it isn’t, so we traverse to the right hand node (4). Whenever a right-hand path is taken, value is adjusted by subtracting the node value of the left-hand path – so in this case, value = 3.5 – 1 = 2.5. Because the right-hand node (4) is a leaf node, the search terminates and returns this node or index. The diagram below shows this process:
The diagram below shows the traversal path through the SumTree for a random value of 6.5:
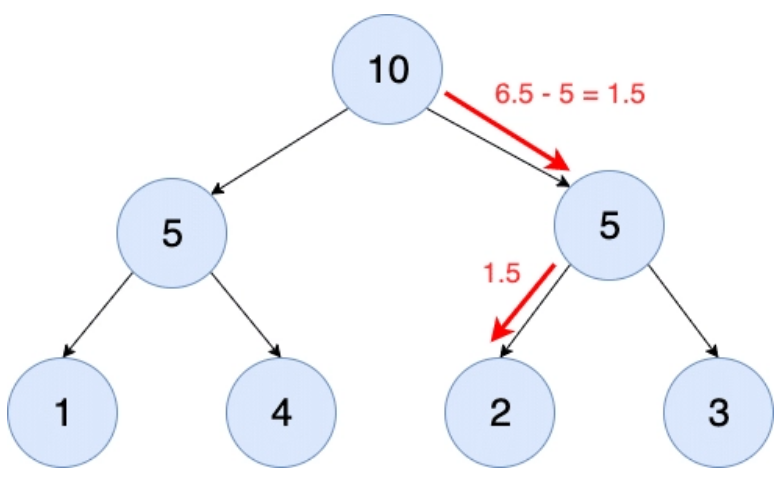
As can be observed initially the right-hand child of the top parent is selected, so the value is decremented by the left-hand node value (6.5 – 5). On the second level, the left-hand child is selected and the algorithm would return the (2) leaf node.
By considering how the SumTree algorithm works, it can be seen how much more efficient it can be than iterating through a cumulative sum array until the correct interval is found. It is also quite easy to update the weight values of the leaf nodes and propagate the changes. All that needs to be done is to take the difference of the change and then add that difference to all upstream node parents. For instance, if the (2) value leaf node is increased to 5, the change is 3. Therefore, its parent (right-hand 5 node) would be increased to 8, and this parent’s parent (the top parent node – 10) would also be increased by 3 to 13.
This is an efficient data structure and algorithm, so let’s see how to implement a SumTree in Python code.
The SumTree in Python
There are many different ways of implementing a SumTree in Python. The code below uses a class to define the structure, and uses recursive functions to both traverse and create the SumTree. Below shows the base class for the SumTree:
class Node:
def __init__(self, left, right, is_leaf: bool = False, idx = None):
self.left = left
self.right = right
self.is_leaf = is_leaf
if not self.is_leaf:
self.value = self.left.value + self.right.value
self.parent = None
self.idx = idx # this value is only set for leaf nodes
if left is not None:
left.parent = self
if right is not None:
right.parent = self
@classmethod
def create_leaf(cls, value, idx):
leaf = cls(None, None, is_leaf=True, idx=idx)
leaf.value = value
return leaf
This class defines information about each node in the tree, but also contains the tree structure within the left, right, and parent properties. The property left refers to the left-hand child of this node, and the property right refers to the right-hand child of this node. The property parent refers, obviously, to the parent of the current node (if it has one). Each of these properties will point to another Node instance. Note that the value property in the class initialization is initialized to be the sum of the values of the left and right child nodes.
The final part of the initialization also sets the parent node of the left and right child nodes to be equal to itself. The create_leaf class method, whose function is to create all the leaf nodes of the tree, takes a weight value and an index as the arguments. In the first line, the leaf variable is defined as an instance of the Node class, with no parents specified. An is_leaf flag of the Node is set to True. This will be used later during the leaf node retrieval function. Finally, the leaf weight is set to the passed value and the leaf node object is returned.
The function below shows how the tree can be created:
def create_tree(input: list):
nodes = [Node.create_leaf(v, i) for i, v in enumerate(input)]
leaf_nodes = nodes
while len(nodes) > 1:
inodes = iter(nodes)
nodes = [Node(*pair) for pair in zip(inodes, inodes)]
return nodes[0], leaf_nodes
The input to this function is a List input which has all the weight values of the leaf nodes. For the simple example we have been working with, this list would be [1, 4, 2, 3]. The first line of the function creates a list of leaf Nodes by calling the create_leaf class method and supplying the passed list values and their respective indices. A leaf_nodes variable, which keeps track of which nodes are the leaves of the tree, is then created and set to be equal to this initial list of nodes.
Next, a more difficult to comprehend loop is entered into. On the first line of the loop, a Python iterator object is created from the nodes list. Note that when a Python iterator object is created from a list of objects like this, each time the iterator is called (via next() or some other operation which extracts the element in the list), that element or object is removed from the iterator. The next line creates a new nodes list of Node objects.
This line requires some unpacking. The zip function in the list comprehension zips together two instances of the iterator. When the “for pair” operates on this zip function, it first extracts one node from inodes, and then extracts the next node from inodes and zips them together. This essentially creates a tuple of (node_1, node_2) in the first round of the for loop, then (node_3, node_4) is the second round of the for loop, and so on. These unpacked tuples i.e. (node_1, node_2) are then used in the list comprehension to create a new instance of Node i.e. the parent node of node_1 and node_2.
In this example, the first time through the while len(nodes) > 1 loop would create a list of 2 nodes – the first node being the parent of leaf nodes (1) and (4), and the second node is the parent of (2) and (3). The length of the list nodes after this first pass would now be 2. On the second pass, a single Node in the list would be created which is the parent of the parents of the leaf nodes, i.e. the parent of the (5) and (5) nodes. This is obviously the top-parent node with a weight value of 10. Because the top-parent or root node has been reached, the length of nodes is no longer > 1 and therefore the while loop exits. The function returns the top-parent node (= nodes[0]) and the list of leaf nodes. Note, that the above function and class definition borrow partially from one of the answers here.
The next function to review is the leaf node retrieval function:
def retrieve(value: float, node: Node):
if node.is_leaf:
return node
if node.left.value >= value:
return retrieve(value, node.left)
else:
return retrieve(value - node.left.value, node.right)
The retrieve function takes a value, in our examples a uniformly sampled random value, and the top-parent node as the first arguments. This function is to be used in a recursive loop, so the first line tests to see if the node is actually the leaf node, meaning that the SumTree traversal has been completed. If this is the case, the function exits and returns the leaf node.
Next, the function checks to see if the current value is less than the left-hand child node value (node.left.value). If so, the function recursively calls itself and passes the value straight-through – in exactly the same manner as the walk-through example I presented above. It also passes the left child node as the second argument to itself. If the value is greater than or equal to the left-hand child node value, the function instead recursively calls itself by passing through the value minus the left-hand child node value, and the right-hand child node as arguments.
If you follow the logic of this recursive loop, you will see that the traversal through the SumTree structure, from the top-parent node to the leaf node, works exactly as described in the walk-through example above. The next two functions are involved in the updating process of the weights of the leaf nodes, the changes of which are then propagated up through the SumTree:
def update(node: Node, new_value: float):
change = new_value - node.value
node.value = new_value
propagate_changes(change, node.parent)
def propagate_changes(change: float, node: Node):
node.value += change
if node.parent is not None:
propagate_changes(change, node.parent)
In the first function, the leaf node that needs to be changed is the first argument, and the new weight value this leaf node should have is passed as the second argument. The first line of the function calculates the change from the current value. The next recursive function propagate_changes is then called – with the arguments being the change variable and the parent of the leaf node. In this function, first, the parent node value is updated by change. Next, the function checks to see if this parent node itself has a parent node. If it doesn’t, that means that the top-parent node has been reached and all the changes have been propagated. If the current node does have a parent, the function calls itself and passes the current node’s parent to the function. In this way, the changes are propagated all the way up from the leaf nodes to the top-parent node.
These functions constitute the core functionality and data structure of the SumTree. In the next section, I’ll show how we can use it and confirm it is working as expected.
Trying out the SumTree
The code below shows how the SumTree is used and demonstrates its correct sampling characteristics:
input = [1, 4, 2, 3]
root_node, leaf_nodes = create_tree(input)
def demonstrate_sampling(root_node: Node):
tree_total = root_node.value
iterations = 1000000
selected_vals = []
for i in range(iterations):
rand_val = np.random.uniform(0, tree_total)
selected_val = retrieve(rand_val, root_node).value
selected_vals.append(selected_val)
return selected_vals
selected_vals = demonstrate_sampling(root_node)
# the below print statement should output ~4
print(f"Should be ~4: {sum([1 for x in selected_vals if x == 4]) / sum([1 for y in selected_vals if y == 1])}")
First, a simple input weight list is created which corresponds to the weights used in the example problem shown above. Next, the tree is created from these inputs using the create_tree function. As shown above, this function returns the top-parent node (called the root_node here) and a list of the leaf nodes. Next, a function has been created to demonstrate how the sampling would work in practice. Note the only input argument is the top-parent/root node – this node contains within itself all the children nodes and associated connections. Within this function, a loop is then entered into with an arbitrarily large number of iterations.
In each iteration, a random value is sampled from a uniform distribution with a range between 0 and the tree_total – which is the same as the value of the top-parent node or root_node. This sampled value is then passed to the retrieve function (along with root_node) which returns the appropriate leaf node whose weight value is then extracted. This value is added to an accumulating list and finally is returned from the function.
The final print statement uses list comprehensions to count the number of times the leaf node with the weight value of 4 has been returned, compared to the number of times the leaf node with the weight value of 1 has been returned. The ratio should be ~4, and the readers can demonstrate that this is indeed the case by running the code. Finally, the second leaf node (with a current weight value of 4) is updated to have a value of 6 and the same process with associated ratio checks is performed:
update(leaf_nodes[1], 6)
selected_vals = demonstrate_sampling(root_node)
# the below print statement should output ~6
print(f"Should be ~6: {sum([1 for x in selected_vals if x == 6]) / sum([1 for y in selected_vals if y == 1])}")
# the below print statement should output ~2
print(f"Should be ~2: {sum([1 for x in selected_vals if x == 6]) / sum([1 for y in selected_vals if y == 3])}")
Again, the reader can check that these ratios come out at values that they should. This concludes the introduction to the SumTree data structure and associated algorithms.
References:
https://www.fcodelabs.com/2019/03/18/Sum-Tree-Introduction/
https://jaromiru.com/2016/11/07/lets-make-a-dqn-double-learning-and-prioritized-experience-replay/
https://adventuresinmachinelearning.com/sumtree-introduction-python/