
- All
- Apache Kafka
- Artificial Intelligence
- Bayesian Statistics
- Big Data
- Cassandra
- Computer Vision
- Data Engineering
- Data Science
- Database
- Deep Learning
- DevOps
- Django
- Docker
- ELK
- Feature Engineering
- Finance
- Keras
- Linear Algebra
- Linux
- Machine Learning
- Mathematics
- MLOps
- NLP
- Python
- PyTorch
- Recommendation Systems
- Reinforcement Learning
- Software Engineering
- Spark
- Statistics and Probability
- Tensorflow
- Time Series
- Uncategorized
2022-11-09
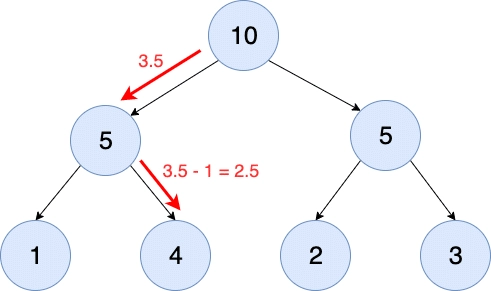
14 mins readWeighted sampling from a list-like collection is an important activity in many applications. Weighted sampling involves selecting samples randomly from […]